a11y heuristic framework
A 5-layer method for running rigorous WCAG analysis with AI as a research partner — not a shortcut
00

PROBLEM
Globo Screening had no formal accessibility audit. The team had no a11y specialist. The deadline was tight. A standard heuristic checklist would have missed half the issues. Automated tools (axe, Lighthouse, WAVE) catch around 30–40% of real WCAG violations — the rest needs human judgment. I led the audit. The challenge wasn't running an evaluation. It was running one that engineering would actually trust enough to act on.
OUTCOMES
192 criteria evaluated 3 pages audited 4 priority waves scoped with engineering 1 replicable method documented and shared
The temptation in 2026 is to point AI at a product and ask for an accessibility report. That produces output that looks rigorous and isn't — generic, inconsistent with the product's real state, prone to citing WCAG criteria incorrectly.
I designed a method where AI amplified analytical capacity without generating conclusions. Every finding came from human judgment first. AI reviewed, verified, and questioned — never authored.
The 5-layer framework

Layer 1 — Independent manual analysis. Two evaluators worked through 64 criteria per screen separately, no comparison until done. Reduces confirmation bias.
Layer 2 — Debrief and consolidation. Disagreements surfaced and resolved. Ambiguous items flagged for deeper investigation.
Layer 3 — AI-assisted review. Each consolidated finding submitted to Claude for critique: imprecise WCAG citations, missing nuance, weak reasoning. AI questioned the analysis. Humans decided what to revise.
Layer 4 — Technical verification. Claude with browser access ran live JavaScript checks: ARIA attributes, CSS values, element measurements. Findings backed by code, not impressions.
Layer 5 — Triangulation. Four independent reports (analyst 1, analyst 2, AI review, technical verification) cross-referenced. Contradictions resolved with code evidence.
Each layer addresses a limitation of the one before it. The triangulation is what gives the final report confidence.
What AI did well
Critical review — flagged WCAG citations that were wrong, surfaced inconsistent logic
Console verification — ran scripts to confirm CSS, ARIA, element dimensions that would take hours manually
Report cross-referencing — identified real contradictions vs. differences in granularity
Structured documentation — turned findings into evidence guides and Confluence-ready reports
What AI didn't do
Generate initial findings autonomously — that was human judgment
Decide what counted as a violation when interpretation was ambiguous
Replace testing with real assistive technology (NVDA, VoiceOver)
Prioritize fixes — the impact×effort matrix was built with engineering
Naming these limits is part of the method. Without them, AI-assisted analysis becomes AI-generated analysis dressed up as rigor.
From audit to action
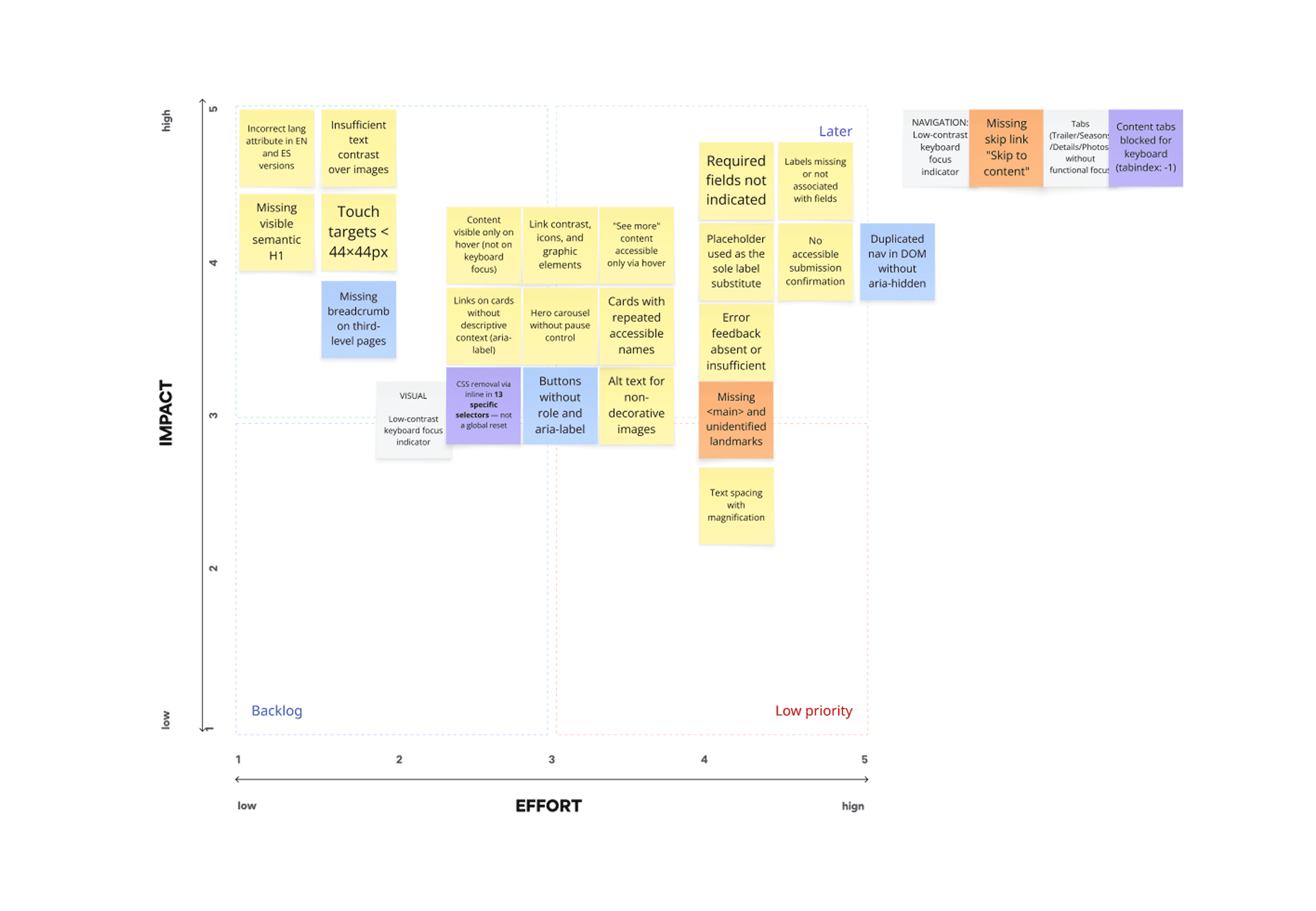
The audit produced 192 evaluated points across three screens. With the dev team, I ran a workshop to plot findings on impact × effort and group corrections into four priority waves.
The output wasn't a report. It was a backlog with evidence — each item tagged with the type of evidence captured (code snippet, contrast measurement, ARIA state, screenshot), so engineers could verify and fix without re-running the diagnosis.
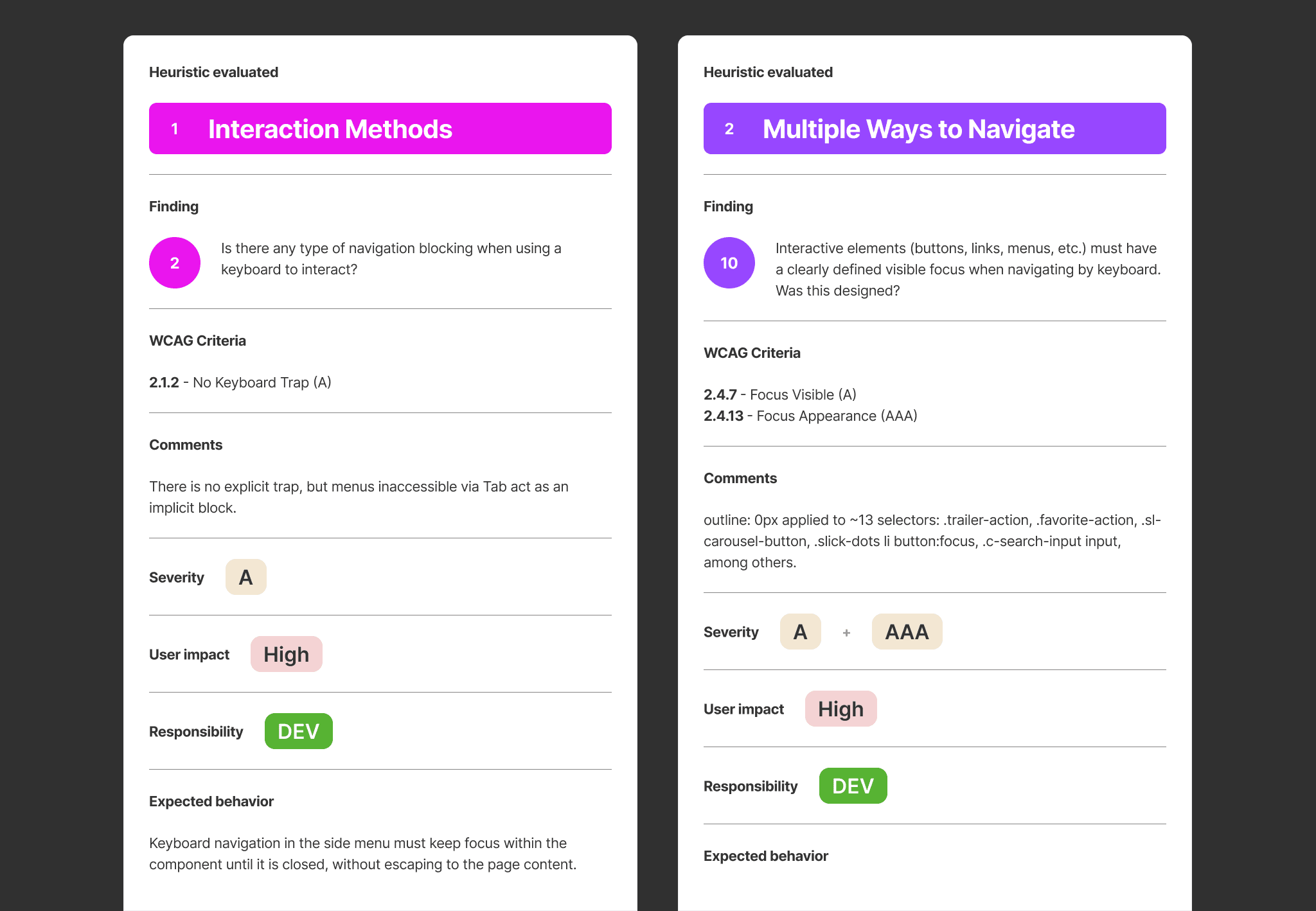
A living document tracks correction progress across the waves.
Reflection
The most useful AI in design isn't the one that generates faster. It's the one that questions better.
This method took longer than a traditional heuristic checklist. The trade wasn't speed — it was depth, reliability, and engineering trust. For an audit that needed to become real engineering work, that trade was the whole point.
YEAR
2023
COMPANY
Globo
ROLE
Senior Product Designer
CATEGORY
UI/UX
see also